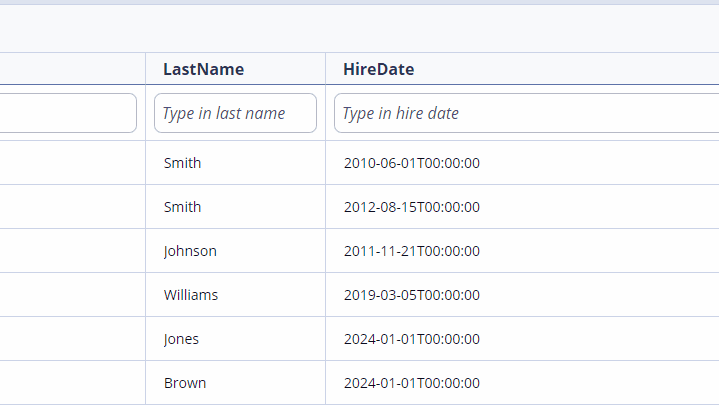
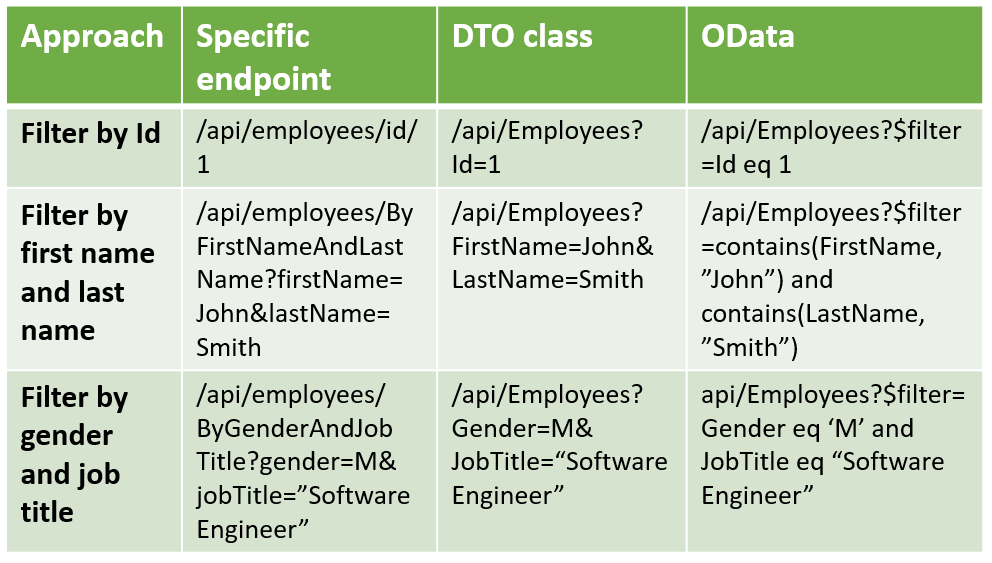
Now, the controller validates $filter clause and just if the filter string contains Department or Department.Id will apply other OData query options: other filters, $orderBy, pagination ($top, $skip) etc.
Now, that we saw how it works with in-memory data, the next question would be:
Does OData for .NET work with storage systems?
Yes. OData offers a versatile approach to data integration, especially with those database providers that are supported by entity framework. Some examples of storage systems would be
- Relational databases: eg. SQL Server.
- NoSql Databases: eg. Cosmos DB
- Although not as straightforward as the ones mentioned above, a custom implementation allows OData to interact with Azure Blob Storage. For example, custom could mean some “translations” from the OData filter in Blob Storage tags.
Using OData comes with many advantages
- For simple APIs with basic CRUD operations, it saves a lot of development and test time. Development because you expose an endpoint which covers a lot of scenarios. Testing time because in the end it is a built-in mechanism that filters, selects, paginates data etc. and if you send the right combination of parameters, you know for sure the response will be correct.
- You minimize the chances that a customer requires new functionality and it’s not there already. Basically, you’ll have more chances to cover a (filtering) scenario even though you didn’t think of it in advance or to deliver something without needing additional implementation and deploys.
- It provides a standardized way to access and manipulate data across different services, platforms, tools. Once you know the model, you can use the standard parameters and operate data exactly how you want.
- It allows you to customize and extend it to fit specific requirements.
But... don’t forget to consider also some red flags before deciding to use it in your project:
- Complexity of the data model
OData works well with simple data models, but if your data model is highly complex with many relationships, it might be challenging to expose it efficiently through OData. Consequently, you might end up with excessive customization or performance issues.
- Performance overhead
OData flexibility in filtering might lead to scenarios with bad performance. Three things to pay attention to:
The first one would be applying OData filters in memory rather than at database level, particularly with large datasets. Fetching large amounts of data in memory and then applying filters can lead to high memory consumption and slow processing times. Always apply filters at the database level. Configure OData to translate query options like ‘$filter’, ‘$orderby’ into SQL queries executed by the database.
The second one: you propagate filters to the database, but OData supports querying across related entities, which can lead to complex SQL queries with multiple joins. If not optimized, these queries can be slow.
Consider using pagination: ‘$skip’ and ‘$top’ options from OData to avoid fetching large amounts of data in a single query.
- Security concerns
Exposing your data through OData endpoints might make it vulnerable to injection attacks or excessive data exposure. A proper authentication and authorization mechanism must be in place. Additionally, you can enhance security by using AutoMapper. With correct DTOs, you can ensure that only necessary data is exposed to the clients. Sensitive data can be excluded from DTOs even though it exists at the entity level.
- Complexity of the business logic
If your application has complex business logic, not just straightforward CRUD operations, OData might not be the best choice. It might require many custom implementations, which will ultimately add even more complexity, making it difficult to maintain.
In Conclusion
The goal of this article was to provide an alternative to classical solutions, not the best, not the worst. OData brings many advantages, but it also presents challenges. Before adopting OData in your projects, evaluate your business requirements, how often they can change or how many variations they have, the knowledge of the team working on it, the time they need to be delivered, etc.
References
- https://www.odata.org/getting-started/understand-odata-in-6-steps/